Omnifocus → Taskwarrior
- Published
- 27 April 2025
- Tagged
I started using OmniFocus at the start of my postgraduate, many many many years ago. Now I'm looking at perhaps switching operating systems in the future, and I want my project list to come with me. Which means finally switching task managers.
TaskWarrior is what I'm currently looking at. It's a CLi-based, open source task management tool which portable to basically any operating system, and has a bunch of extensions.
But exporting tasks and projects from one project, and importing them to another, is a big deal. Let's see how hard it can be.
The big picture
The good news is that OmniFocus has a good export system, and TaskWarrior has a good import system.
OmniFocus exports to xml
If you open OmniFocus, you can export your current database to file by selecting File > Export:
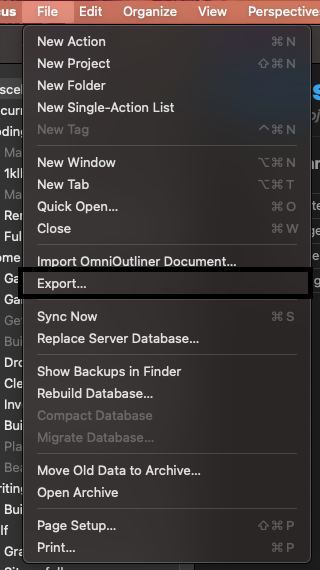
The location of the Export menu item in OmniFocus
This will prompt you to save an .ofocus file somewhere on your computer, but if you happen to inspect it in terminal or even just gently rename it to remove the .ofocus extension, OS X will reveal to you what it really is: a folder.
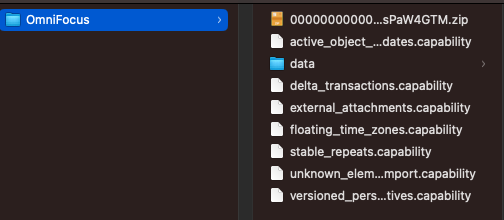
The contents of a typical .ofocus "file".
There's a bunch of stuff in here, but there's always one zip file, named something crazy and random-looking, which is actually a zipped .xml file. And if you unzip and open that...
The contents of that zipped xml file.
Not quite complete nonsense - this is actually a file containing every folder, project, context, perspective, and task that currently exists in your OmniFocus database. And this is gold.
TaskWarrior imports from json
You can find the specifics here, but the good news is that even though you could make a program to systematically call TaskWarrior and add task after task, you can also run a bulk import on a JSON file. There are some things we'll need to work around - for example, TaskWarrior doesn't have a good handle on nested tasks, and projects and folders are a much more nebulous concept - but we can indeed work around them.
As we go through the next few steps, I'll be referring back to their JSON spec above to work out how to handle our various task and project properties.
OK, so how do we export this stuff?
The first thing will be to read the XML file. I'm doing this in ruby, my glue language of choice, and in ruby the standard XML parsing gem is nokogiri.
Here's a script to load in contents.xml, check through the top-level elements, and see what they are.
require 'nokogiri'
doc = File.open("contents.xml"){ |f| Nokogiri::XML(f) }
doc.root.children.each do |elem|
puts elem.name
end
This will provide you with the following element types:
- attachment: A file attachment
- context: A task context
- folder: A project folder
- perspective: A saved perspective
- setting: A document setting
- task: A project or task (OmniFocus treats projects as subsets of tasks)
- task-to-tag: Basically a many-to-many join table between tasks and contexts
We're going to be focusing on the folder and task elements here.
Here's a simple ruby script which iterates through all your tasks, showing each task's name:
require 'nokogiri'
doc = File.open("contents.xml"){ |f| Nokogiri::XML(f) }
doc.search(":root > task").each do |t|
puts t.at("name").text
end
We're using CSS-style selection in doc.search - Nokogiri also supports XPath, but I'm most familiar with CSS so I'm going to be using that for this example. If you've run this, you should see a big ol' list of task and project names in your console. As I mentioned, OmniFocus makes little structural distinction between projects and tasks, as they both share many properties (name, contexts, due date, repetition rule, etc.). The project-specific properties for a project are stored in the project element underneath the task object. In fact, we can split our tasks into actual tasks and projects pretty handily:
require 'nokogiri'
doc = File.open("contents.xml"){ |f| Nokogiri::XML(f) }
ALL_TASKS_AND_PROJECTS = doc.search(":root > task")
puts "I have #{ALL_TASKS_AND_PROJECTS.length} tasks/projects!"
ALL_TASKS = ALL_TASKS_AND_PROJECTS.select{ |elem| elem.at("project").children.length == 0 }
puts " #{ALL_TASKS.length} of these are tasks"
ALL_PROJECTS = ALL_TASKS_AND_PROJECTS.select{ |elem| elem.at("project").children.length > 0 }
puts " #{ALL_PROJECTS.length} of these are projects"
As mentioned, TaskWarrior doesn't really treat projects as first-class citizens, so we want to focus on just exporting tasks. We'll deal with projects as we go. Let's have a first stab at making something resembling TaskWarrior's import JSON format:
require 'nokogiri'
require 'json'
doc = File.open("contents.xml"){ |f| Nokogiri::XML(f) }
ALL_TASKS_AND_PROJECTS = doc.search(":root > task")
ALL_TASKS = ALL_TASKS_AND_PROJECTS.select{ |elem| elem.at("project").children.length == 0 }
taskwarrior_import_array = ALL_TASKS.map{ |elem|
{ 'description' => elem.at("name").text }
}
File.open("import.json", "w"){ |io| io.puts JSON.pretty_generate(taskwarrior_import_array) }
This will generate a JSON array of tasks, all given the correct name. It almost looks like this could be a valid import to TakWarrior - except it's not, of course. Let's check TaskWarrior's documentation on the subject:
At a minimum, a valid task contains:
- uuid
- status
- entry
- description
OK, so as well as a task description (which we've now added), we need a uuid (a unique identifier in a standard form), an entry (the date/time at which the task was created), and a status (active/complete/etc). Let's see what we can do.
Generating a UUID
TaskWarrior's documentation states that:
A UUID is a 32-hex-character lower case string, formatted in this way:
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxAn example:
296d835e-8f85-4224-8f36-c612cad1b9f8
While OmniFocus does use unique IDs for its tasks, it doesn't use this format. The easiest thing for us to do is to create them whole cloth, one per new task.
It turns out you can really easily create those in ruby using the securerandom package:
require 'securerandom'
SecureRandom.uuid # => A nice UUID
Adding an entry field
TaskWarrior is pretty strict about date/time formats:
Dates are rendered in ISO 8601 combined date and time in UTC format using the template:
YYYYMMDDTHHMMSSZAn example:
20120110T231200ZNo other formats are supported.
Annoyingly, OmniFocus stores its dates and times in a slightly different format. Here's an example of OmniFocus' added field, which represents when the task was added to the program, and is analagous to TaskWarrior's entry field:
<added>2017-05-15T09:19:04.940Z</added>
You could parse this into a Time object, then output using strftime. Or you could just regex the task into submission:
tw_time = of_time.gsub(/[-:]/, "").gsub(/\..*Z$/, "Z")
Adding status
Ignoring recurring tasks, TaskWarrior recognises four statuses: pending, deleted, completed, and waiting. All our tasks will be considered to be pending for now, just to make things easy.
Handily, pending tasks don't need any more information.
A bare bones legal export
So let's look at the code which will give us the bare minimum setup in TaskWarrior from our OmniFocus data:
require 'nokogiri'
require 'json'
require 'securerandom'
doc = File.open("contents.xml"){ |f| Nokogiri::XML(f) }
ALL_TASKS_AND_PROJECTS = doc.search(":root > task")
ALL_TASKS = ALL_TASKS_AND_PROJECTS.select{ |elem| elem.at("project").children.length == 0 }
taskwarrior_import_array = ALL_TASKS.map{ |elem|
{
'description' => elem.at("name").text,
'entry' => elem.at("added").text.gsub(/[-:]/, "").gsub(/\..*Z$/, "Z"),
'uuid' => SecureRandom.uuid,
'status' => 'pending'
}
}
File.open("import.json", "w"){ |io| io.puts JSON.pretty_generate(taskwarrior_import_array) }
Not too shabby, all told - but what about our other fields?
Advanced migration
Nothing under this section is vital, but chances are you'll want to bring one or more of the following data types along with you.
Projects
As mentioned, TaskWarrior treats projects as more of an auxiliary item than a first-class citizen. On the one hand, this means we won't be keeping any cool project-level info like project-wide tags, start dates, or due dates, but it also means that we don't have to try creating a relational database just to port things over.
TaskWarrior allows each task to have a project, which can in turn be nested within one or more project groups. TaskWarrior's projects take the form: Proj1.Proj2.Proj3, where Proj3 is nested inside a parent project Proj2, which is in turn nested inside a parent project Proj1.
In contrast, OmniFocus has a more complex folder-project-task heirarchy. Projects cannot be children of other Projects, but can be children of Folders, which can in turn be children of other Folders. Tasks can be children of Projects, or they can be children of other tasks.
Whew.
If you're using all of the levels of OmniFocus, well, you're gonna have to collapse some of that in TaskWarrior[1]. The main thing that'll give us headaches is nested tasks. I went through my projects before exporting to TaskWarrior and just ensured that every project was a simple list of tasks with no nesting - if you want to keep your nesting in your exported file, you may need to do some more exploration of the file structure.
OmniFocus generates its task and project heirarchy as follows:
- Every task has a
<task>child element with anidrefattribute. This attribute corresponds to the id of the task or project that this task is a child of. If this is absent, this task has no parent (ie it's an inbox task). - Every project has a
<project>child element, which in turn has a<folder>child element with anidrefattribute. Again, this corresponds to the parent folder (if any). - Every folder may have a
<folder>child element, which (if it does) has anidrefattribute. And this corresponds to the parent folder.
Given all that, we can create a kind of "path" for each task by combining these in sequence. We'll be using recursion to ensure this can always trace the task's heirarchy back to the root of our OmniFocus document. We have to tread carefully as it's difficult to tell whether a task is a child of another task, or whether it's a child of a project, without inspecting the parent element.
require 'nokogiri'
require 'json'
require 'securerandom'
doc = File.open("contents.xml"){ |f| Nokogiri::XML(f) }
ALL_TASKS_AND_PROJECTS = doc.search(":root > task")
ALL_TASKS = ALL_TASKS_AND_PROJECTS.select{ |elem| elem.at("project").children.length == 0 }
ALL_FOLDERS = doc.search(":root > folder")
def path_to_folder(f)
if f.nil?
return "<ERROR>"
end
folder_name = f.at("name").text
parent_element = f.at("folder")
if parent_element.nil? || parent_element["idref"].nil?
# No parent - path is just the folder name
folder_name
else
# Parent - path = parent path + this name
parent_folder = ALL_FOLDERS.find{ |f| f["id"] == parent_element["idref"] }
path_to_folder(parent_folder) + "." + folder_name
end
end
def path_to_taskproject(tp, top = true)
elem_is_project = tp.at("project").children.length > 0
elem_name = tp.at("name").text
if elem_is_project
parent_element = tp.at("project folder")
if parent_element["idref"]
# Parent folder - path = parent path + this name
parent_folder = ALL_FOLDERS.find{ |f| f["id"] == parent_element["idref"] }
path_to_folder(parent_folder) + "." + elem_name
else
# No parent - path is just the project name
elem_name
end
else
# Task - go through <task> element
parent_element = tp.at("task")
if parent_element["idref"]
# Has a parent: path = parent path + this name
parent_taskproject = ALL_TASKS_AND_PROJECTS.find{ |tp| tp["id"] == parent_element["idref"] }
if top
path_to_taskproject(parent_taskproject, false)
else
path_to_taskproject(parent_taskproject, false) + "." + elem_name
end
else
# No parent - inbox task!
nil
end
end
end
And we can test this as follows:
sample_task = ALL_TASKS.sort_by{ rand }.first
puts "Path for '#{sample_task.at("name").text}':"
puts path_to_taskproject(sample_task)
At this point, we can add this to our output! The project field is just a string value, after all:
taskwarrior_import_array = ALL_TASKS.map{ |elem|
{
'description' => elem.at("name").text,
'entry' => elem.at("added").text.gsub(/[-:]/, "").gsub(/\..*Z$/, "Z"),
'uuid' => SecureRandom.uuid,
'project' => path_to_taskproject(elem),
'status' => 'pending'
}
}
Contexts
OmniFocus' Contexts map nicely to TaskWarrior's tag attribute. Unlike contexts, tags don't naturally support a heirarchy, and to be honest I suspect trying to implement heirarchical tags would make your filters and reports somewhat unwieldy in TaskWarrior. Heirachical context may be an indicator of some other sorting criterion, which could be a candidate for setting up through User-defined attributes (something I haven't really gotten into yet, but I'm keen to try out?).
I didn't end up bringing my contexts through to TaskWarrior, partly because most of the tasks I'm tracking have one real context (viz: Computer) and partly because I wanted to reset my current context system and remove some needless complexity from my projects.
Given all that, let's look at how we could map contexts to tags, ignoring your context heirarchy for now.
Our first job will be to extract a task's contexts from the OmniFocus xml file. Each task may have a context child element, which links (via idref) to exactly one context - but tasks can have multiple contexts, so this isn't a guarantee we'll catch everything of use. Thus, we must use the one join table OmniFocus encodes into its xml file - the task-to-tag element grouping.
require 'nokogiri'
require 'json'
doc = File.open("contents.xml"){ |f| Nokogiri::XML(f) }
ALL_TASKS_AND_PROJECTS = doc.search(":root > task")
ALL_TASKS = ALL_TASKS_AND_PROJECTS.select{ |elem| elem.at("project").children.length == 0 }
# Contexts
ALL_CONTEXTS = doc.search(":root > context")
CONTEXT_TASK_JOIN = doc.search(":root > task-to-tag")
def context_ids(task_id)
CONTEXT_TASK_JOIN
.select{ |ctj| ctj.at("task")["idref"] == task_id }
.map{ |ctj| ctj.at("context")["idref"] }
end
def context(id)
ALL_CONTEXTS.find{ |c| c["id"] == id }
end
def context_name(id)
c = context(id)
return c if c.nil?
return c.at("name").text
end
def task_contexts(task_id)
context_ids(task_id).map{ |id| context_name(id) }
end
sample_task = ALL_TASKS.first
st_name = sample_task.at("name").text
puts "#{st_name}: #{task_contexts(sample_task["id"]).join(', ')}"
The above snippet pulls out that join table and uses it to identify every link between a task and a context. Then, it looks up that context to get the context's name. We can then add that to our JSON - TaskWarrior expects a task's tag attribute to be an array of string values, so it's not too much of an issue to just add those context labels in there.
What's that? You'd like to keep the context heirarchy? Well, you do you - the following code will do that:
def full_context_name(id)
c = context(id)
return c if c.nil?
c_name = c.at("name").text
c_context = c.at("context")
if c_context && c_context["idref"]
return full_context_name(c_context["idref"]) + "." + c_name
else
return c_name
end
end
Recurrence
Recurrence is, as far as I can tell, a bugbear for every single task management application. You want this task to repeat every week on Saturday, huh? What if you haven't completed it by the time next Saturday rolls around? What if you complete it on Friday? Do you want the task to restart the following day? Do you want the task to be due again in a week, or just to reappear on your task list in a week?
OmniFocus does a lot to make task recurrence work exactly how you want. It's a bit complex when you first encounter it, but it'll do whatever you need it to.
TaskWarrior's recurrence rules are a little more basic. This means any fancy recurrences you have set up in OmniFocus, well, won't translate over, and even some basic functionality (like scheduled dates) doesn't work well with recurrence. In fact, at this stage I'd be hesitant to even try providing a migration strategy for recurrence. I'm planning on reviewing my current recurring tasks and either reimplementing them in TaskWarrior, or setting up some sort of calendar reminder system. It's a work in progress.
That became quite a bit longer than expected, mainly due to code snippets and the like. I hope if you've reached this far in the article, it's been of use as you shift into TaskWarrior. Who knows - within a couple of months, I may be looking for alternative task management apps. But in the meantime, I'm hoping to keep this all documented in the garden.
It's possible to replicate complex task groupings with task dependencies, which isn't something I've delved into yet. Perhaps at a later date I'll explore that. ↩︎